ConsistentNeRF: Enhancing Neural Radiance Fields with 3D Consistency for Sparse View Synthesis
- Shoukang Hu1
- Kaichen Zhou2
- Kaiyu Li1
- Longhui Yu2
- Lanqing Hong4
- Tianyang Hu4
- Zhenguo Li✉4
- Gim Hee Lee✉5
- Ziwei Liu✉1
-
1S-Lab, Nanyang Technological University 2University of Oxford
3Peking University 4Huawei Noah's Ark Lab 5National University of Singapore
- ✉Corresponding Author
TL;DR: ConsistentNeRF Enhances Neural Radiance Fields with 3D Consistency for Sparse View Synthesis.
Abstract
Neural Radiance Fields (NeRF) has demonstrated remarkable 3D reconstruction capabilities with dense view images. However, its performance significantly deteriorates under sparse view settings. We observe that learning the 3D consistency of pixels among different views is crucial for improving reconstruction quality in such cases. In this paper, we propose ConsistentNeRF, a method that leverages depth information to regularize both multi-view and single-view 3D consistency among pixels. Specifically, ConsistentNeRF employs depth-derived geometry information and a depth-invariant loss to concentrate on pixels that exhibit 3D correspondence and maintain consistent depth relationships. Extensive experiments on recent representative works reveal that our approach can considerably enhance model performance in sparse view conditions, achieving improvements of up to 94% in PSNR, 76% in SSIM, and 31% in LPIPS compared to the vanilla baselines across various benchmarks, including DTU, NeRF Synthetic, and LLFF.
Links


DTU Dataset (3 View Input)
| NeRF | DSNeRF | DietNeRF | InfoNeRF | |
|
|
|
|
|
|
| MipNeRF | RegNeRF | ConsistentNeRF (Ours) | ||
|
|
|
|
NeRF Dataset (3 View Input)
| NeRF | DSNeRF | DietNeRF | InfoNeRF | |
|
|
|
|
|
|
| MipNeRF | RegNeRF | ConsistentNeRF (Ours) | ||
|
|
|
|
LLFF Dataset (3 View Input)
| NeRF | DSNeRF | DietNeRF | InfoNeRF | |
|
|
|
|
|
|
| MipNeRF | RegNeRF | ConsistentNeRF (Ours) | ||
|
|
|
|
Method Overview
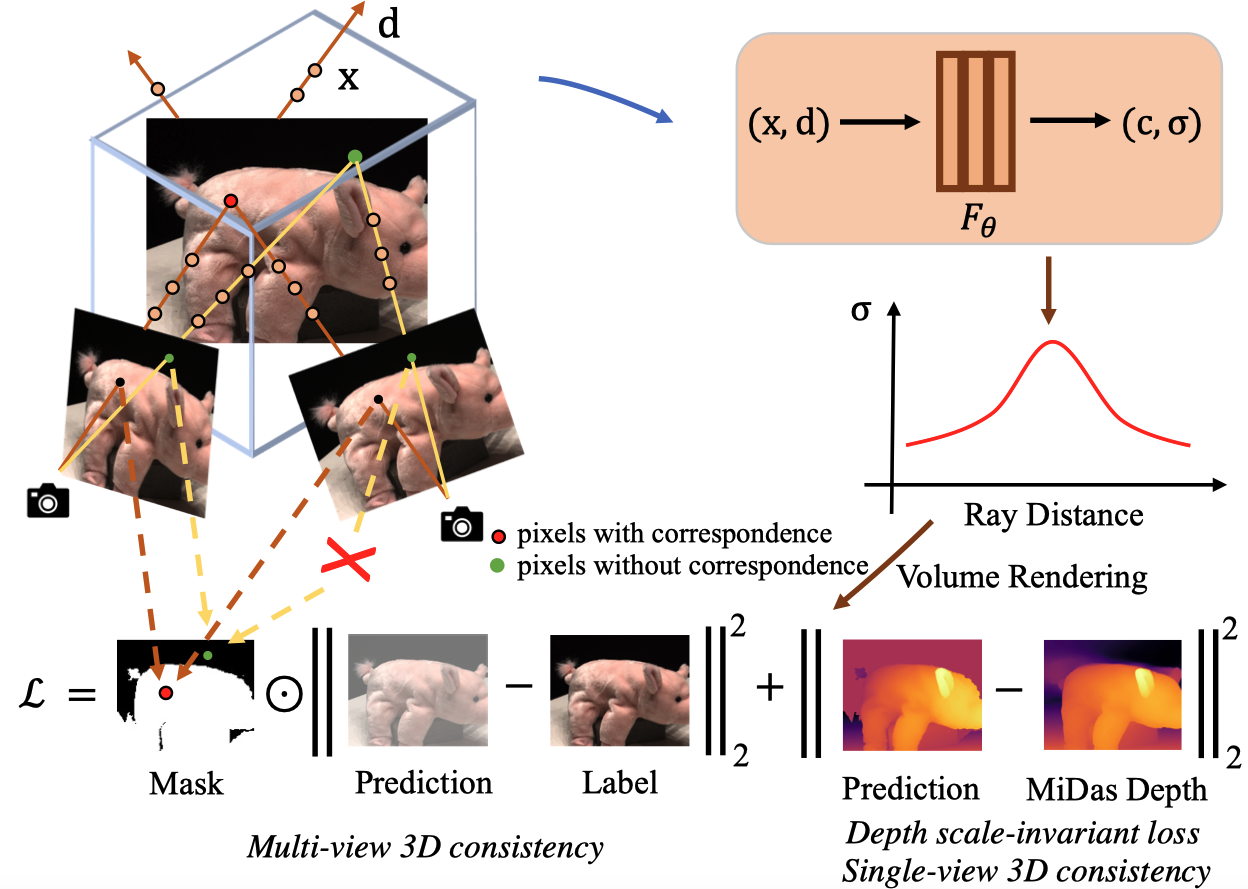 Figure 1. ConsistentNeRF Framework.
Figure 1. ConsistentNeRF Framework.
We regularize multi-view 3D consistency by utilizing the multi-view depth correspondence among different views to mask pixels satisfying 3D correspondence (the red point) or not (the green point) and construct the loss based on the mask information. We also regularize single-view 3D consistency by constructing a depth scale-invariant loss function based on the monocular depth predicted from state-of-the-art MiDas model.