|
I am a Senior Researcher at Microsoft Research Asia.
Before that, I was a Research Scientist at Sony AI and a Research Fellow at MMLab@NTU, working with Prof. Ziwei Liu.
I obtained the Ph.D. degree from The Chinese Univeristy of Hong Kong under the supervision of Prof. Xunying Liu,
and the B.E. Degree from the University of Electronic Science and Technology of China.
Google Scholar | GitHub | CV |

|
|
I am interested in exploring multiple modalities to enhance the advancement of perception, reconstruction, and generation, including
|
|
|
|
(* indicates equal contribution, + denotes corresponding author) |
|
|
Tianqi Liu*, Zihao Huang*, Zhaoxi Chen, Guangcong Wang, Shoukang Hu, Liao Shen, Huiqiang Sun, Zhiguo Cao, Wei Li+, Ziwei Liu+ International Conference on Computer Vision (ICCV), 2025. [Paper] [Project Page] [Code]  
Free4D is a tuning-free framework for 4D scene generation. |

|
Shoukang Hu, Takuya Narihira, Kazumi Fukuda, Ryosuke Sawata, Takashi Shibuya, Yuki Mitsufuji Preprint [Paper] [Project Page] [Code]  
HumanGif formulates the single-view-based 3D human novel view and pose synthesis as a single-view-conditioned human diffusion process, utilizing generative priors from foundational diffusion models. |
|
|
Zihao Huang, Shoukang Hu, Guangcong Wang, Tianqi Liu, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu. Conference on Computer Vision and Pattern Recognition (CVPR), 2025. [Paper] [Project Page] [Code] WildAvatar is a large-scale dataset from YouTube with 10,000+ human subjects, designed to address the limitations of existing laboratory datasets for avatar creation. |
|
|
Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu. European Conference on Computer Vision (ECCV), 2024 [Paper] [Project Page] [Code]  
MVSGaussian is a Gaussian-based method designed for efficient reconstruction of unseen scenes from sparse views in a single forward pass. It also offers high-quality initialization for fast training and real-time rendering. |

|
Shoukang Hu, Ziwei Liu Conference on Computer Vision and Pattern Recognition (CVPR), 2024. [Paper] [Project Page] [Code]  
GauHuman learns articulated Gaussian Splatting from monocular videos with both fast training (1~2 minutes) and real-time rendering (up to 189 FPS). |

|
Shoukang Hu, Fangzhou Hong, Tao Hu, Liang Pan, Weiye Xiao, Haiyi Mei, Lei Yang, Ziwei Liu International Journal of Computer Vision (IJCV). [Paper] [Project Page] [Code]  
HumanLiff learns the layer-wise 3D human generative model with a unified diffusion process. |

|
Shoukang Hu, Kaichen Zhou, Kaiyu Li, Longhui Yu, Lanqing Hong, Tianyang Hu, Zhenguo Li, Gim Hee Lee, Ziwei Liu Preprint [Paper] [Project Page] [Code]  
ConsistentNeRF Enhances Neural Radiance Fields with 3D Consistency for Sparse View Synthesis. |
|
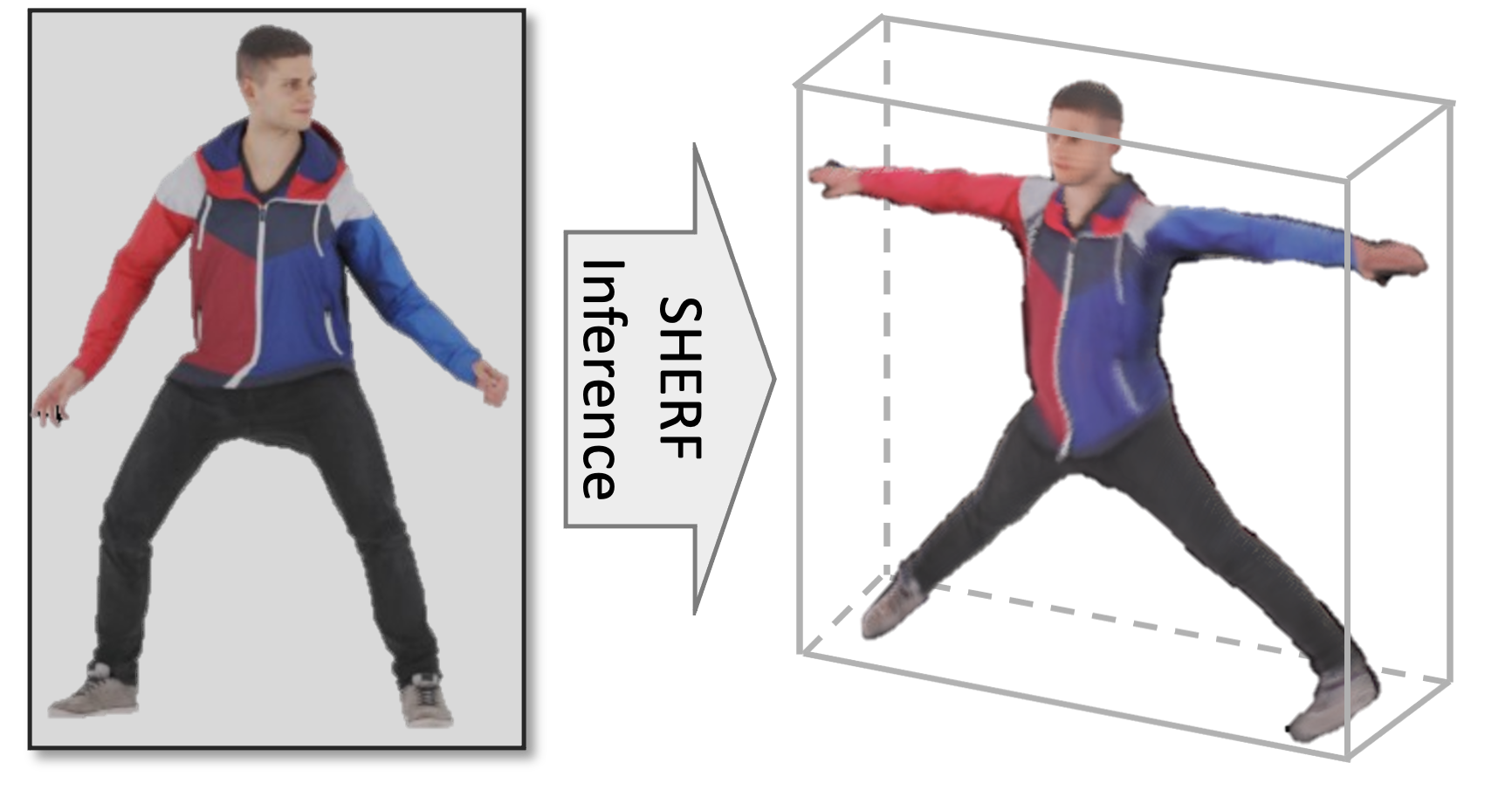
Shoukang Hu*, Fangzhou Hong*, Liang Pan, Haiyi Mei, Lei Yang, Ziwei Liu International Conference on Computer Vision (ICCV), 2023. [Paper] [Project Page] [code]  
SHERF learns a Generalizable Human NeRF to animate 3D humans from a single image. |
|
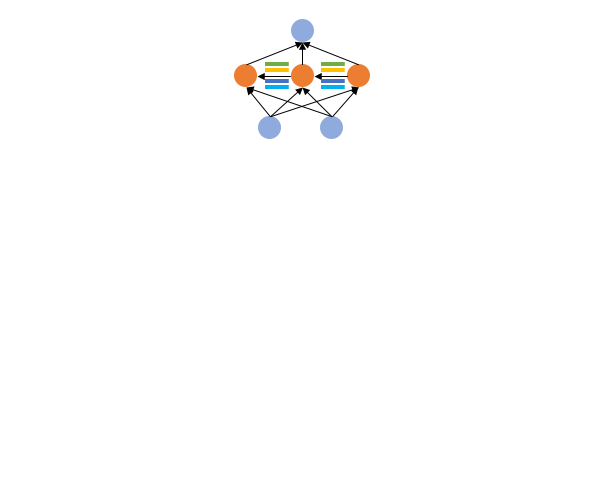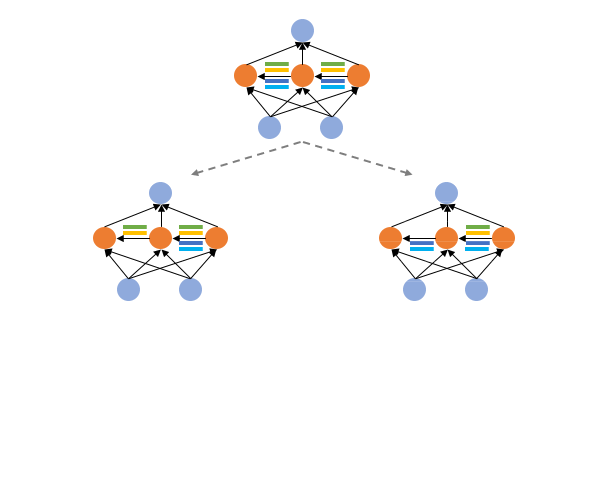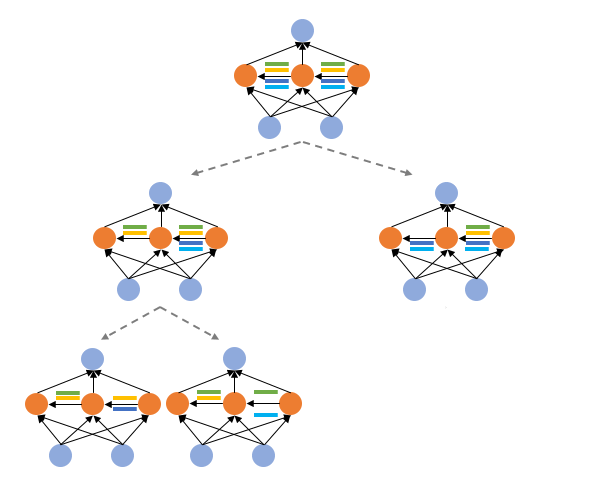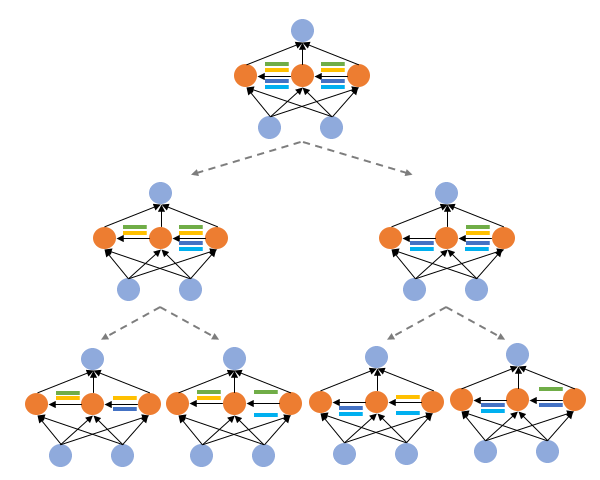
Shoukang Hu*, Ruocheng Wang*, Lanqing Hong, Zhenguo Li, Cho-Jui Hsieh, Jiashi Feng International Conference on Learning Representations (ICLR), 2022. [Paper] [Code] [Zhihu]  
GM-NAS formulates supernet partitioning as a graph clustering problem and utilizes gradient matching score as the splitting criterion. Notably, we achieve 80.6% accuracy on ImageNet under 600 flops constraint. |
|
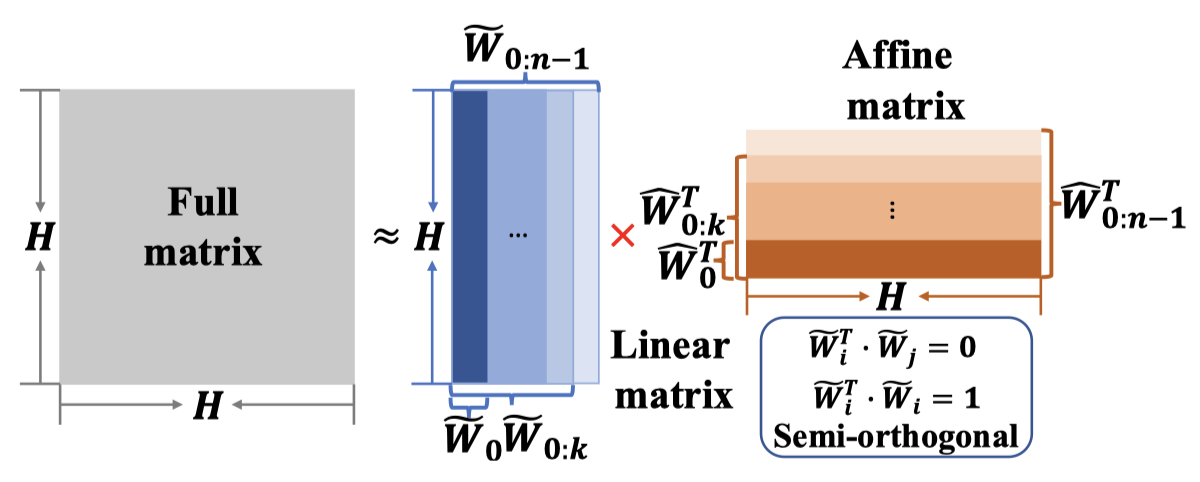
Shoukang Hu, Xurong Xie, Mingyu Cui*, Jiajun Deng*, Shansong Liu, Jianwei Yu, Mengzhe Geng, Xunying Liu, Helen Meng International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2021. IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP). [Paper] [Code]  
We achieve 9.9%/11.1% WER on Hub5'00/Rt03 test sets of 300-Hour Switchboard Task with 10.8M parameters. |
|
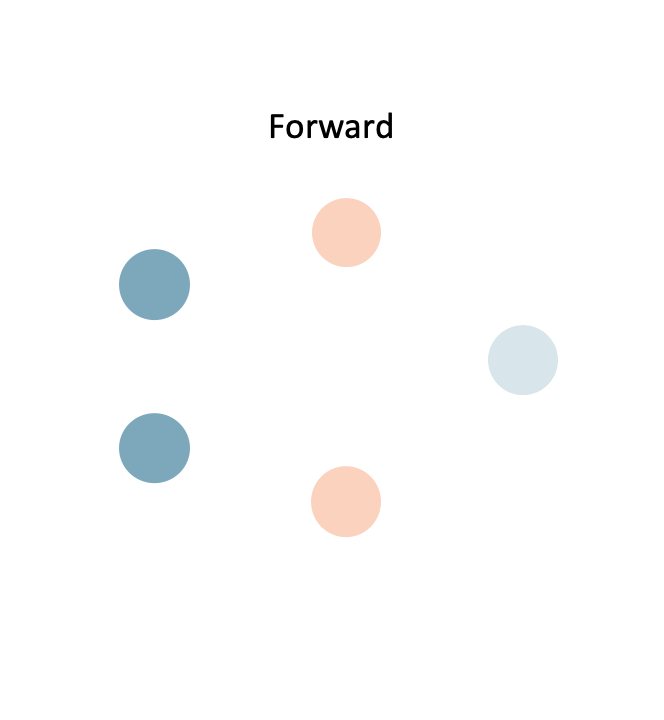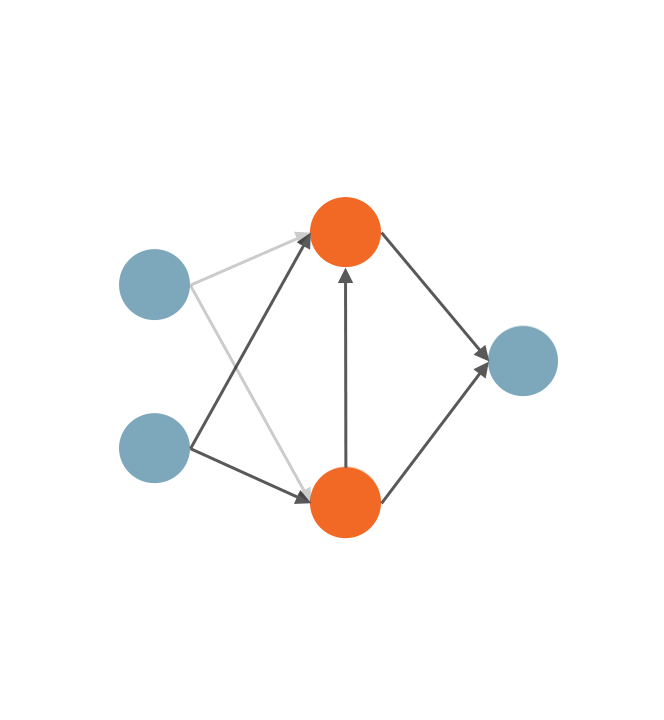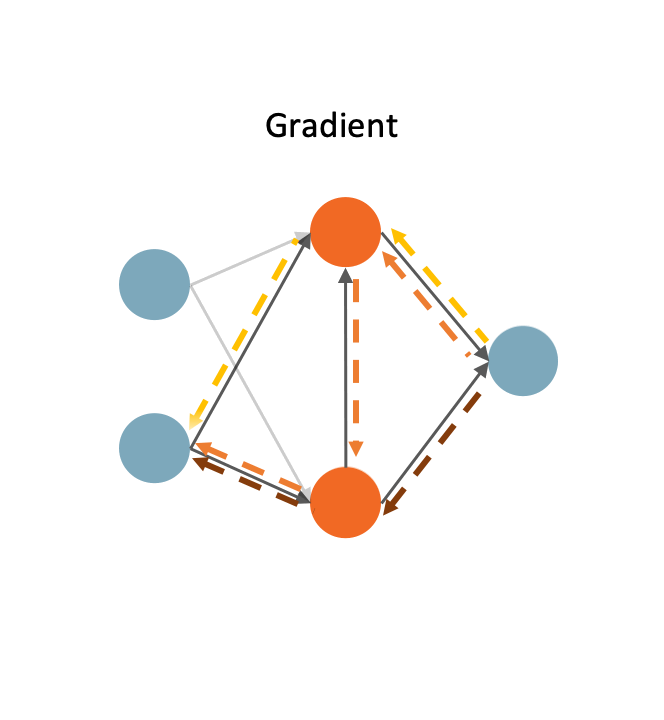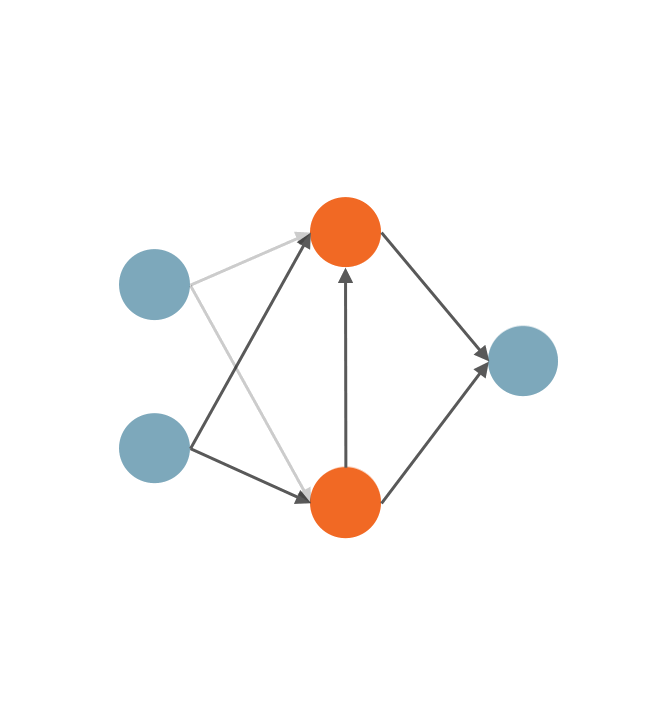
Sirui Xie*, Shoukang Hu*, Xinjiang Wang, Chunxiao Liu, Jianping Shi, Xunying Liu, Dahua Lin International Conference on Artificial Intelligence and Statistics (AISTATS), 2021. [Paper] [Code] [Zhihu]  
Our analysis focuses on three observed searching patterns of differentiable NAS: 1) they search by growing instead of pruning; 2) wider networks are more preferred than deeper ones; 3) no edges are selected in bi-level optimization. |
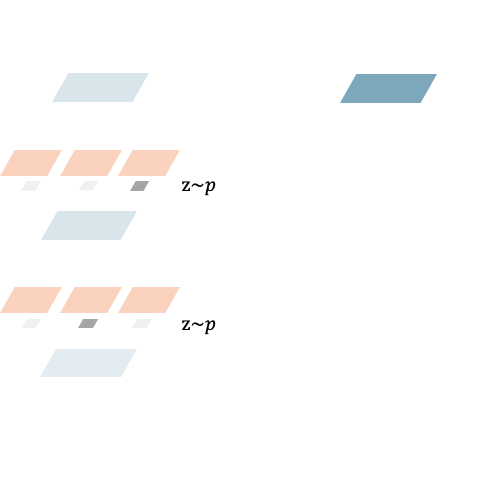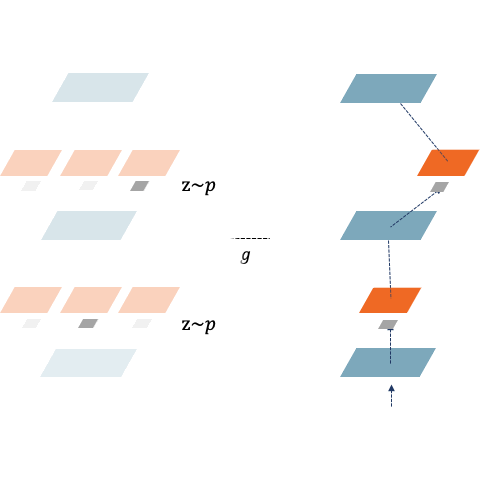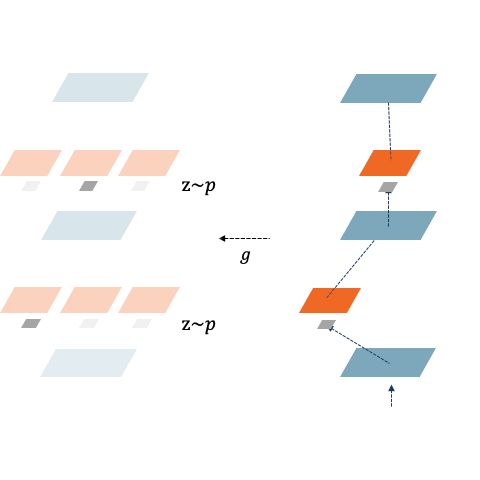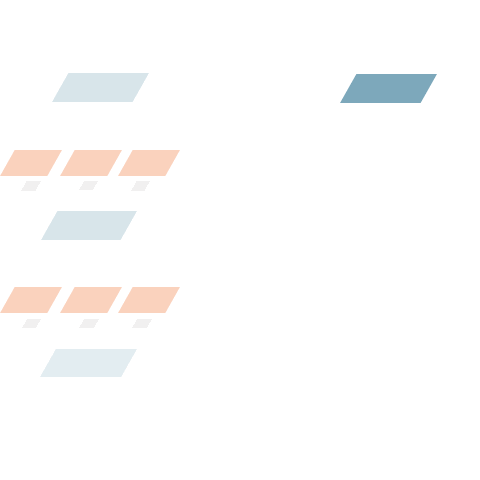
|
Shoukang Hu*, Sirui Xie*, Hehui Zheng, Chunxiao Liu, Jianping Shi, Xunying Liu, Dahua Lin Conference on Computer Vision and Pattern Recognition (CVPR), 2020. [Paper] [Code] [Zhihu]
We propose a new problem definition for NAS, i.e., task-specific end-to-end NAS. Our DSNAS got a final 122 review score. |
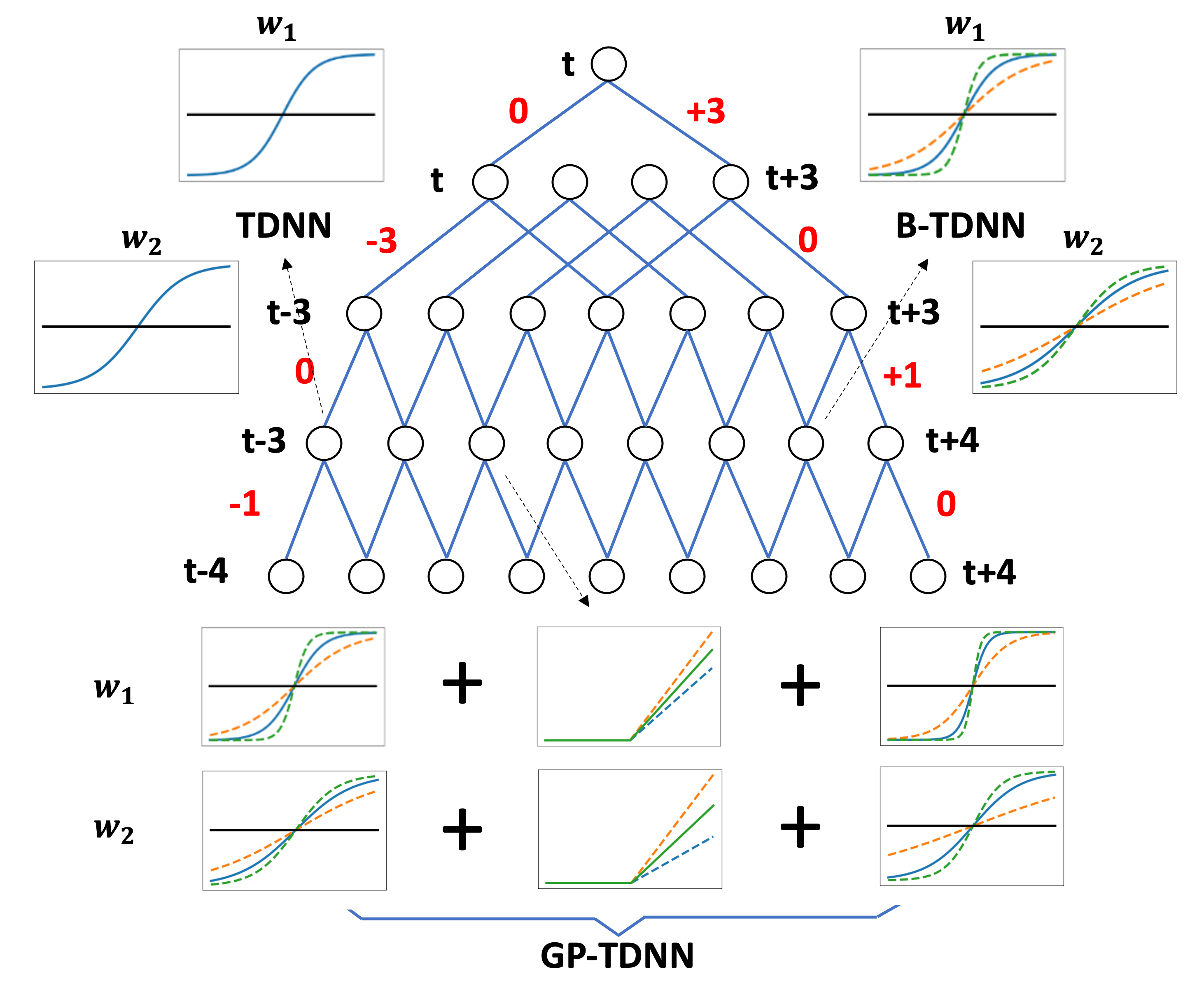
|
Shoukang Hu, Xurong Xie, Max W. Y. Lam, Shansong Liu, Jianwei Yu, Zi Ye, Mengzhe Geng, Xunying Liu, Helen Meng International Speech Communication Association (INTERSPEECH), 2018. International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019. International Speech Communication Association (INTERSPEECH), 2019. ISCA Yajie Miao Memorial Grant Winner In IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP). [Paper] [Code]  
We improve generalization ability of LF-MMI ASR with 10.4%/11.8% WER on Hub5'00/Rt03 test sets of 300-Hour Switchboard task. |
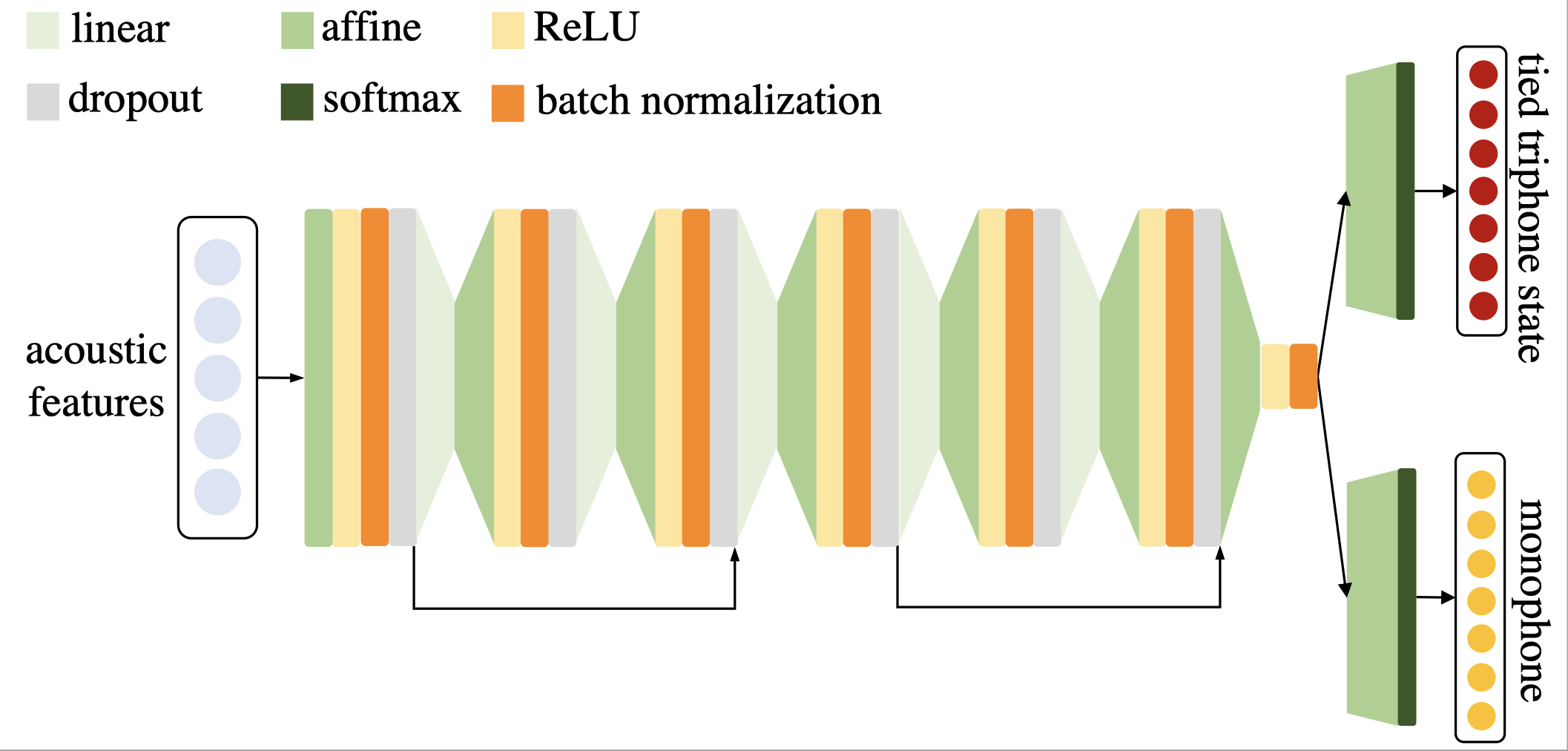
|
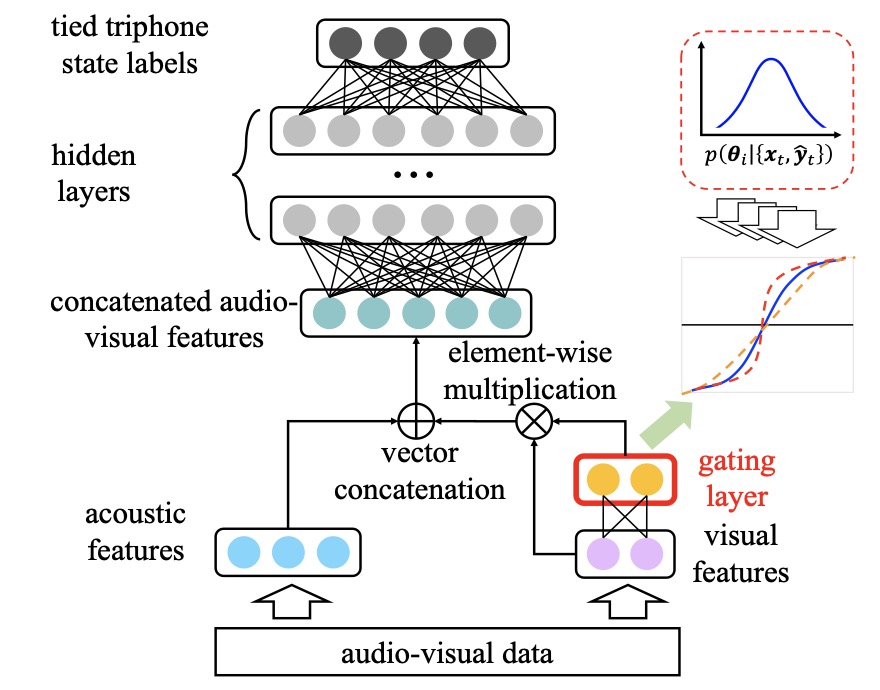
Shansong Liu*, Mengzhe Geng*, Shoukang Hu*, Xurong Xie*, Mingyu Cui, Jianwei Yu, Xunying Liu, Helen Meng In IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP). [Paper] [Demo] [Demo Paper] We report our recent progress in CUHK Dysarthric Speech Recognition System. |
|
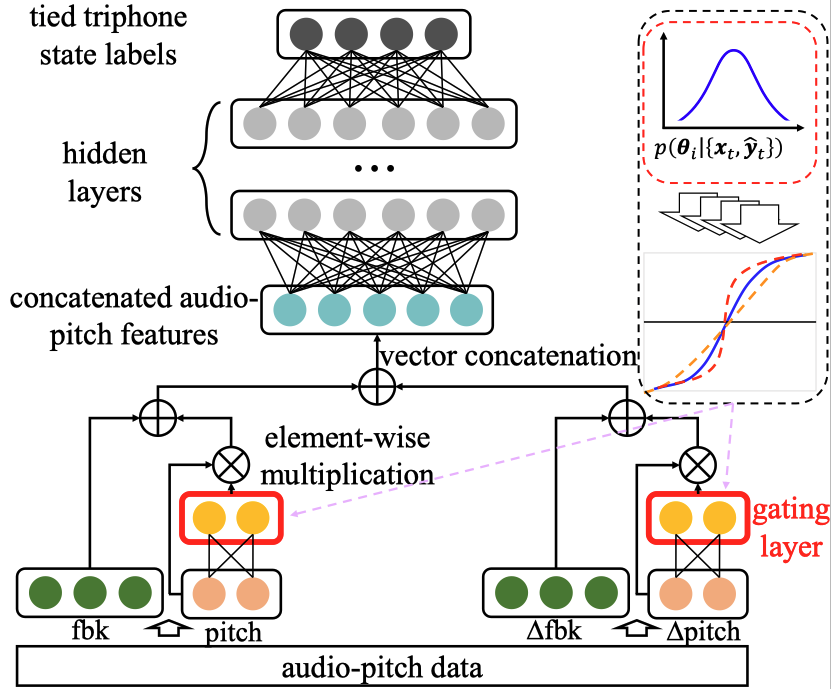
Shansong Liu*, Shoukang Hu*, Xunying Liu, Helen Meng International Speech Communication Association (INTERSPEECH), 2019. [Paper] [Demo] [Demo Paper] We investigate the use of pitch features in Disordered Speech Recognition. |
|
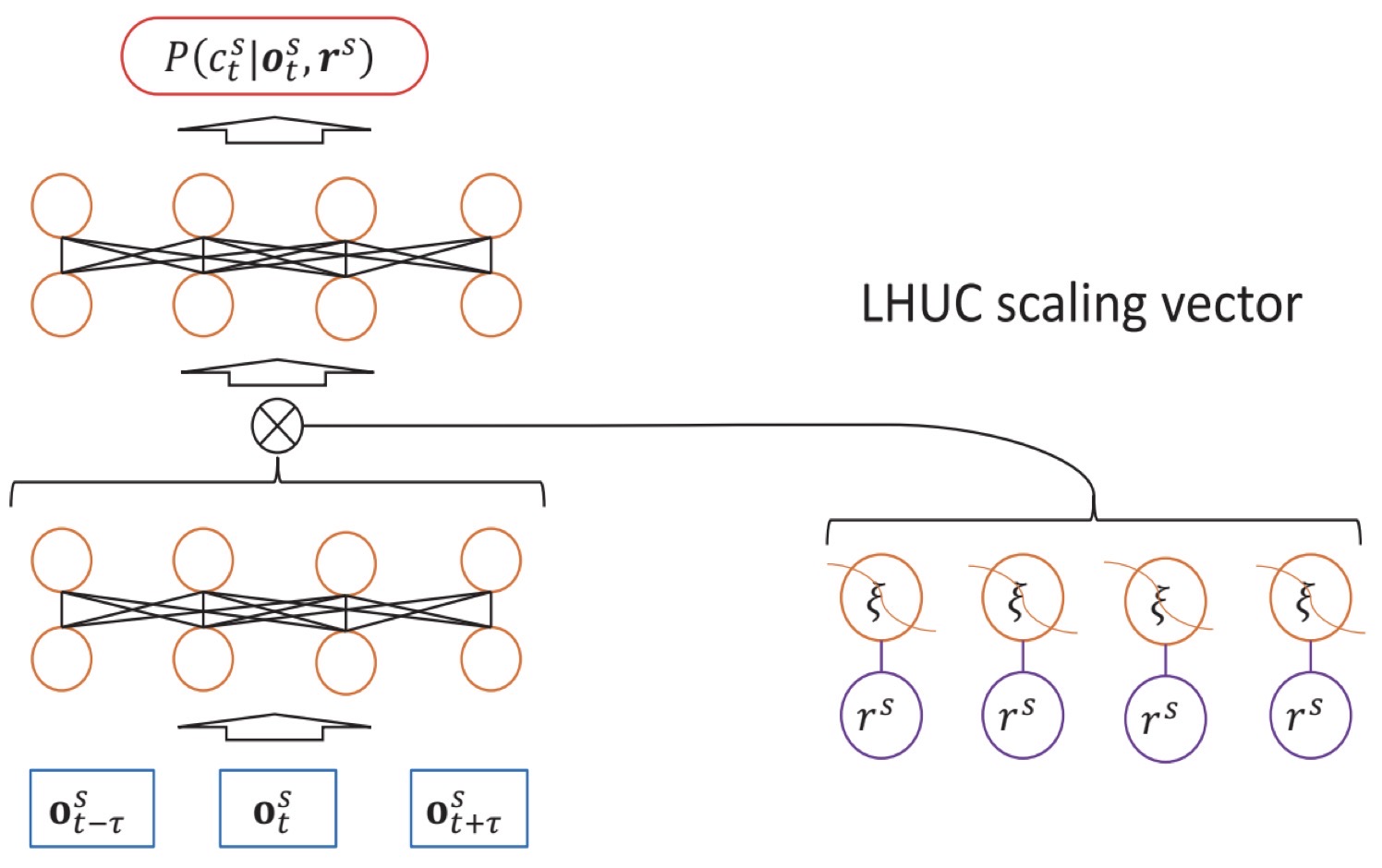
Xurong Xie, Xunying Liu, Tan Lee, Shoukang Hu, Lan Wang International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2019. Best Student Paper Award [Paper] [Code] BLHUC achieves 9.7%/10.7% WER on Hub5'00/Rt03 test sets of 300-Hour Switchboard task. |
|
Shansong Liu, Shoukang Hu, Yi Wang, Jianwei Yu, Rongfeng Su, Xunying Liu, Helen Meng International Speech Communication Association (INTERSPEECH), 2019. Best Student Paper Award Nomination [Paper] [Demo] [Demo Paper] Bayesian Gated Neural Networks achieves 25.7% WER on UASpeech corpus. |
|
|
|
|
| |