HumanLiff: Layer-wise 3D Human Generation with Diffusion Model
- Shoukang Hu1
- Fangzhou Hong1
- Tao Hu1
- Liang Pan1
- Weiye Xiao2
- Haiyi Mei2
- Lei Yang2
- Ziwei Liu1
- 1S-Lab, Nanyang Technological University
- 2Sensetime Research
TL;DR: HumanLiff learns the layer-wise 3D human generative model with a unified diffusion process.

Abstract
3D human generation from 2D images has achieved remarkable progress through the synergistic utilization of neural rendering and generative models. Existing 3D human generative models mostly generate a clothed 3D human as an undetectable 3D model in a single pass, while rarely considering the layer-wise nature of a clothed human body, which often consists of the human body and various clothes such as underwear, outerwear, trousers, shoes, etc. In this work, we propose HumanLiff, the first layer-wise 3D human generative model with a unified diffusion process. Specifically, HumanLiff firstly generates minimal-clothed humans with tri-plane features in a canonical space, and then progressively generate 3D humans conditioned on the previous 3D generation. In this way, the 3D human generation is thus formulated as a sequence of diffusion-based 3D conditional generation. To reconstruct more fine-grained 3D humans with tri-plane representation, we propose a tri-plane shift operation which splits each plane in the tri-plane into three sub-planes and shifts sub-planes to achieve feature grid subdivision. To further enhance the controllability of 3D generation with 3D layered conditions, HumanLiff uses a UNet encoder to hierarchically fuse tri-plane features along with 3D layered conditions to facilitate the 3D diffusion model training. Extensive experiments on two layer-wise 3D human datasets, SynBody (synthetic) and TightCap (real-world), validate that HumanLiff significantly outperforms state-of-the-art methods in layer-wise 3D human generation.
Links


SynBody (Synthetic) Visualization Results
| Layer 0 | Layer 1 | Layer 2 | Layer 3 | |
| EG3D |
|
|
|
|
| EVA3D |
|
|
|
|
| Rodin |
|
|
|
|
|
Humanliff (Ours) |
|
|
|
|
TightCap (Real-world) Visualization Results
| Layer 0 | Layer 1 | Layer 2 | Layer 3 | |
| EG3D |
|
|
|
|
| EVA3D |
|
|
|
|
| Rodin |
|
|
|
|
|
Humanliff (Ours) |
|
|
|
|
Method Overview
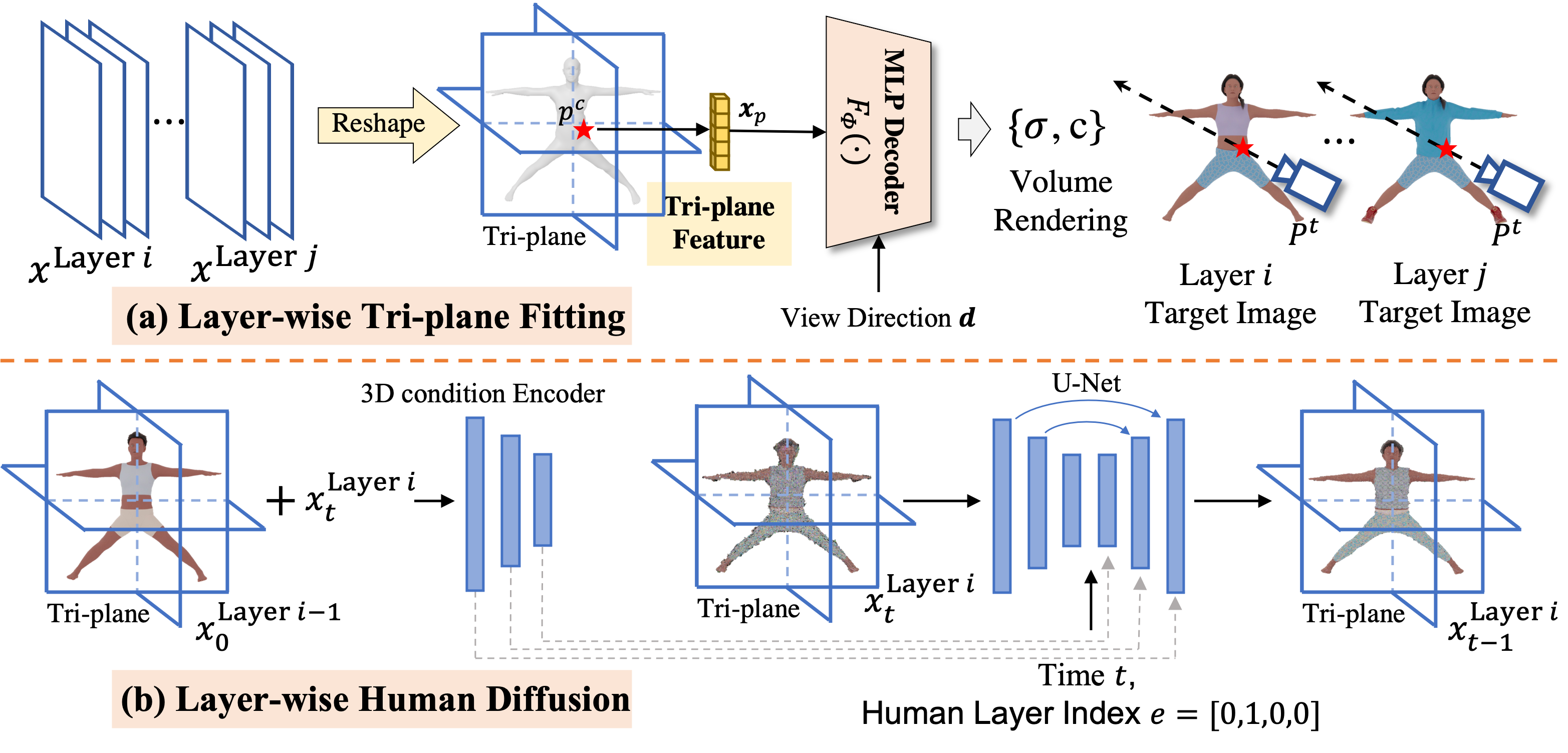 Figure 1. HumanLiff Framework.
Figure 1. HumanLiff Framework.
a) The first stage reconstructs 3D representations, i.e., tri-planes, from multi-view images with a shared decoder. In order to spatially align 3D features, inverse LBS is used to transform humans with different shapes or poses to the canonical spaces. b) In the second stage, we learn layer-wise human diffusion models using the reconstructed tri-planes from the first stage. To facilitate sequential conditional generation, we apply a UNet encoder to hierarchically incorporate tri-plane features from previous steps with diffused tri-plane features as inputs to the denoising network.
Demo Video
Bibtex
@article{HumanLiff,
title={HumanLiff: Layer-wise 3D Human Generation with Diffusion Model},
author={Hu, Shoukang and Hong, Fangzhou and Hu, Tao and Pan, Liang and Mei, Haiyi and Xiao, Weiye and Yang, Lei and Liu, Ziwei},
journal={arXiv preprint},
year={2023}
}