SHERF: Generalizable Human NeRF from a Single Image
- Shoukang Hu*1
- Fangzhou Hong*1
- Liang Pan1
- Haiyi Mei2
- Lei Yang2
- Ziwei Liu✉1
- 1S-Lab, Nanyang Technological University
- 2Sensetime Research
- *Equal Contribution
- ✉Corresponding Author
input image
motion seq 1
motion seq 2
input image
motion seq 1
motion seq 2
input image
motion seq 1
motion seq 2
input image
motion seq 1
motion seq 2


| Input Image | NHP | MPS-NeRF | SHERF (ours) |

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|

|
|
|
|
| Input Image | NHP | MPS-NeRF | SHERF (ours) |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| Input Image | Motion seq 1 | Motion seq 2 | |

|
|
|
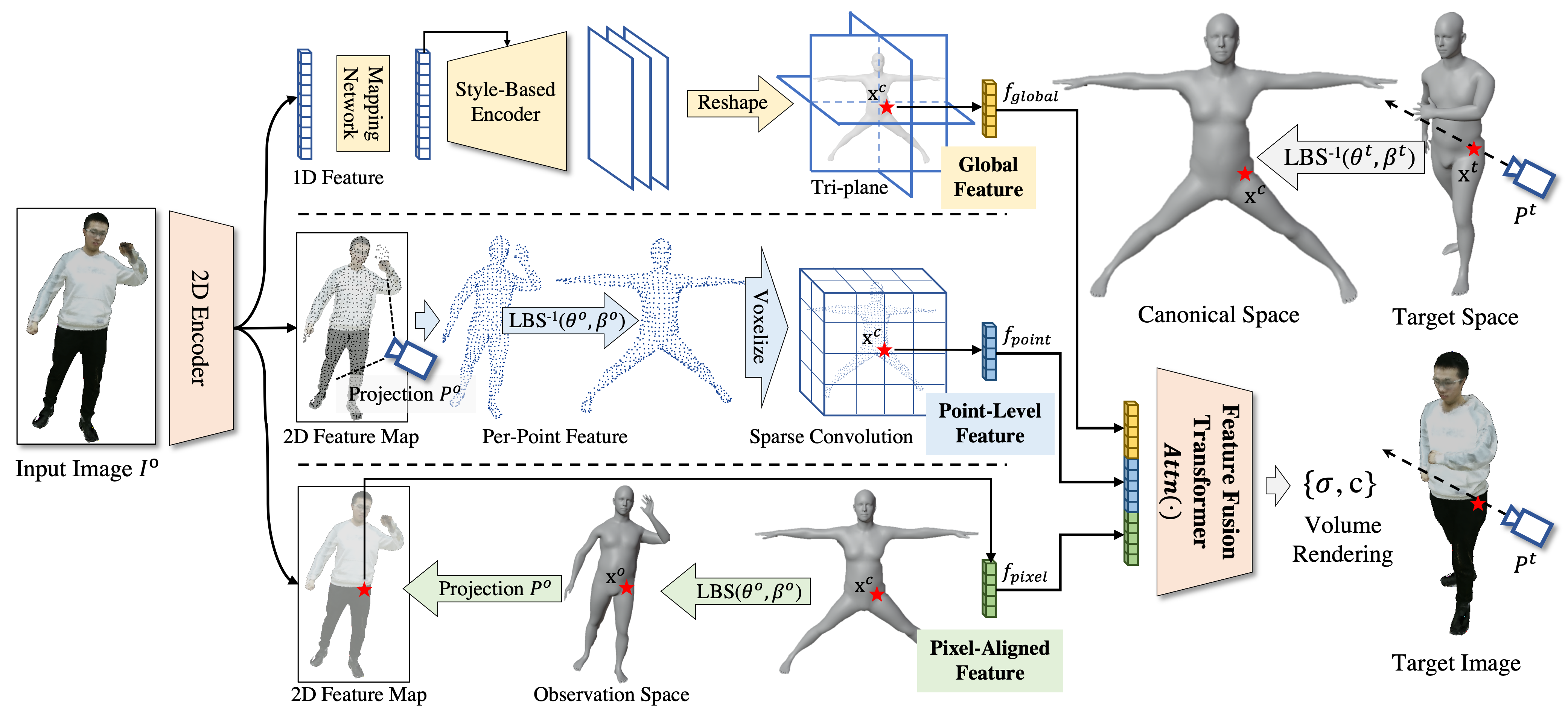 Figure 1. SHERF Framework.
Figure 1. SHERF Framework.
To render the target image, we first cast rays and sample points in the target space. The sample points are transformed to the canonical space through inverse LBS. We then query the corresponding 3D-aware global, point-level, and pixel-aligned features. The deformed points, combined with the bank of features, are input into the feature fusion transformer and NeRF decoder to get the RGB and density, which are further used to produce the target image through volume rendering.
@article{SHERF,
title={SHERF: Generalizable Human NeRF from a Single Image},
author={Hu, Shoukang and Hong, Fangzhou and Pan, Liang and Mei, Haiyi and Yang, Lei and Liu, Ziwei},
journal={arXiv preprint},
year={2023}
}
There are lots of wonderful related works that might be of interest to you.
3D Human Generation
+ EVA3D is a high-quality unconditional 3D human generative model that only requires 2D image collections for training.
+ AvatarCLIP generate and animate diverse 3D avatars given descriptions of body shapes, appearances and motions in a zero-shot way.
2D Human Generation
+ Text2Human proposes a text-driven controllable human image generation framework.
+ StyleGAN-Human scales up high-quality 2D human dataset and achieves impressive 2D human generation results.
Motion Generation
+ MotionDiffuse is the first diffusion-model-based text-driven motion generation framework with probabilistic mapping, realistic synthesis and multi-level manipulation ability.
+ Bailando introduces an actor-critic-based reinforcement learning scheme to the GPT to achieve synchronized alignment between diverse motion tempos and music beats.