GauHuman: Articulated Gaussian Splatting from Monocular Human Videos
- S-Lab, Nanyang Technological University
- CVPR 2024
TL;DR: GauHuman learns articulated Gaussian Splatting from monocular videos with both fast training (1~2 minutes) and real-time rendering (up to 189 FPS).
Abstract
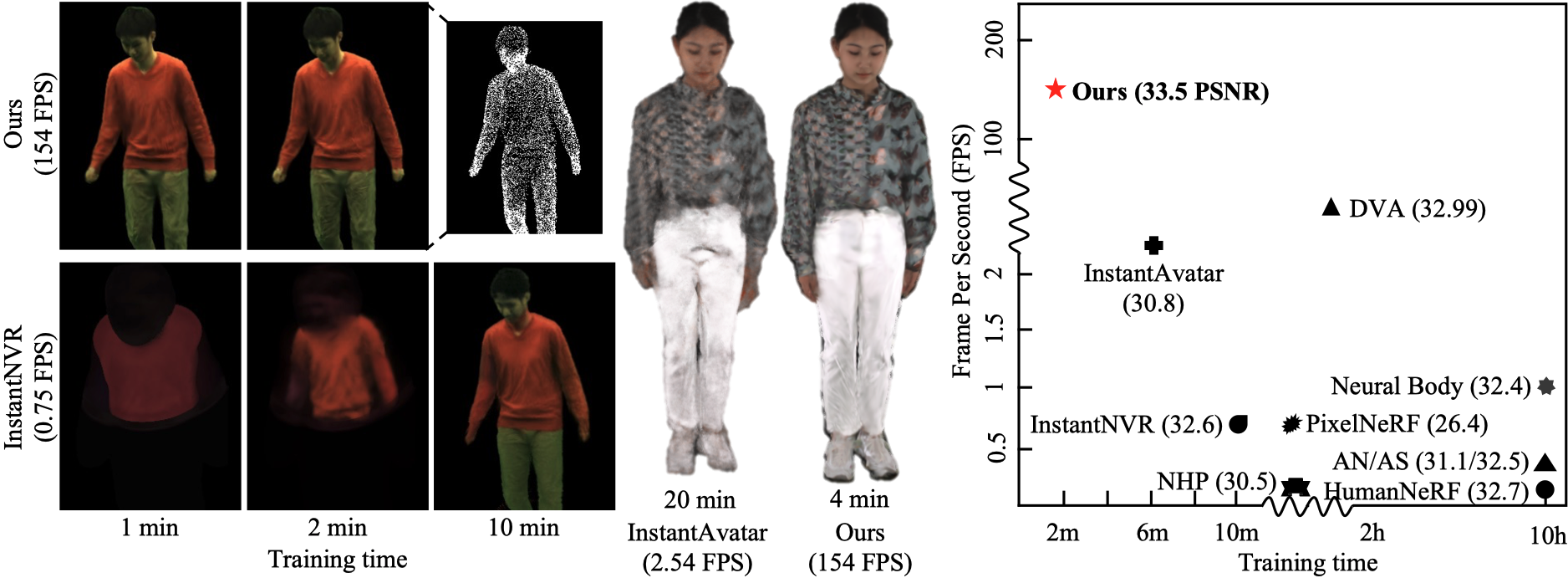
We present, GauHuman, a 3D human model with Gaussian Splatting for both fast training (1~2 minutes) and real-time rendering (up to 189 FPS), compared with existing NeRF-based implicit representation modelling frameworks demanding hours of training and seconds of rendering per frame. Specifically, GauHuman encodes Gaussian Splatting in the canonical space and transforms 3D Gaussians from canonical space to posed space with linear blend skinning (LBS), in which effective pose and LBS refinement modules are designed to learn fine details of 3D humans under negligible computational cost. Moreover, to enable fast optimization of GauHuman, we initialize and prune 3D Gaussians with 3D human prior, while splitting/cloning via KL divergence guidance, along with a novel merge operation for further speeding up. Extensive experiments on ZJU_Mocap and MonoCap datasets demonstrate that GauHuman achieves state-of-the-art performance quantitatively and qualitatively with fast training and real-time rendering speed. Notably, without sacrificing rendering quality, GauHuman can fast model the 3D human performer with ~13k 3D Gaussians.
Links

Novel View Synthesis Visualization Results
| Model (Training, Rendering) | Model (Training, Rendering) | Model (Training, Rendering) |
|
|
|
|
| DVA (1.5h, 16.5FPS) | InstantAvatar (3min, 4.15FPS) | GauHuman (Ours, 1min, 189FPS) |
|
|
|
|
| DVA (1.5h, 16.5FPS) | InstantAvatar (3min, 4.15FPS) | GauHuman (Ours, 1min, 189FPS) |
|
|
|
|
| DVA (1.5h, 10.5FPS) | InstantAvatar (6min, 2.54FPS) | GauHuman (Ours, 2min, 154FPS) |
|
|
|
|
| DVA (1.5h, 10.5FPS) | InstantAvatar (6min, 2.54FPS) | GauHuman (Ours, 2min, 154FPS) |
|
|
|
|
| AS (10h, 0.14FPS) | InstantAvatar (20min, 20.48FPS) | GauHuman (Ours, 4min, 152FPS) |
Method Overview
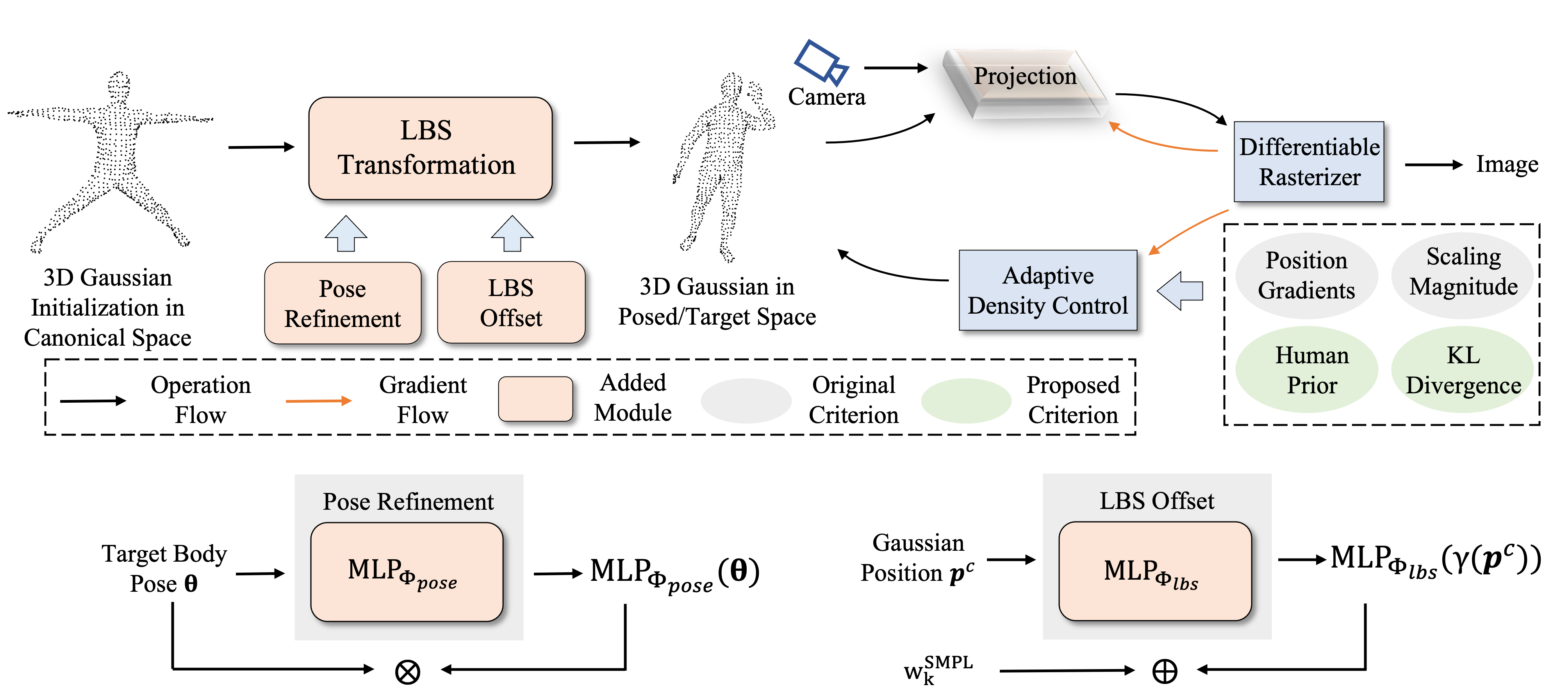 Figure 1. GauHuman Framework.
Figure 1. GauHuman Framework.
We first initialize 3D Gaussians' positions from SMPL vertex points. Then we incorporate pose refinement module and LBS weight field to learn the LBS transformation to transform 3D Gaussians from canonical space to posed space. During optimization, a tile-based differentiable rasterizer is applied to enable fast rendering. To adaptively control the number of 3D Gaussians, we further propose to use human prior (e.g., SMPL) and KL divergence measure to regulate the split, clone, merge, and prune process.
Demo Video
Bibtex
@article{GauHuman,
title={GauHuman: Articulated Gaussian Splatting for Real-Time 3D Human Rendering},
author={Hu, Shoukang and Liu, Ziwei},
journal={arXiv preprint},
year={2023}
}